The notation \(P(y = 1 \,|\, \mathbf{x})\) reads “the probability that \(y = 1\)given\(\mathbf{x}\).” This is a conditional probability—the probability of default, given that we observe a particular set of feature values.
Here \(\mathbf{x} = (x_1, x_2, \ldots, x_p)'\) is a \(p\)-vector of features (attributes) for an observation, and \(\boldsymbol{\beta} = (\beta_1, \beta_2, \ldots, \beta_p)'\) is the corresponding \(p\)-vector of coefficients we need to learn.
The Linear Predictor
Let’s define \(z = \beta_0 + \boldsymbol{\beta}' \mathbf{x}\) as the linear predictor. Writing out the dot product:
The coefficient \(\beta_j\) tells us how a one-unit increase in \(x_j\) affects the log-odds:
If \(\beta_j > 0\): higher \(x_j\) increases the probability of \(y = 1\)
If \(\beta_j < 0\): higher \(x_j\) decreases the probability of \(y = 1\)
If \(\beta_j = 0\): \(x_j\) has no effect
We can also interpret coefficients as odds ratios: \(e^{\beta_j}\) is the multiplicative change in odds for a one-unit increase in \(x_j\). If \(\beta_j = 0.5\), then \(e^{0.5} \approx 1.65\): each one-unit increase multiplies the odds by 1.65 (a 65% increase).
Fitting Logistic Regression: The Loss Function
How do we find the best coefficients \(\beta_0, \boldsymbol{\beta}\)? Like any ML model, we define a loss function and minimize it.
For observation \(i\) with features \(\mathbf{x}_i\) and label \(y_i\), let \(\hat{p}_i = P(y_i = 1 \,|\, \mathbf{x}_i)\) be our predicted probability. Intuitively:
If \(y_i = 1\): we want \(\hat{p}_i\) close to 1 (predict high probability for actual positives)
If \(y_i = 0\): we want \(\hat{p}_i\) close to 0 (predict low probability for actual negatives)
The binary cross-entropy loss (also called log loss) captures this:
When \(y_i = 1\), the loss is \(-\ln(\hat{p}_i)\), which is small when \(\hat{p}_i\) is close to 1. When \(y_i = 0\), the loss is \(-\ln(1 - \hat{p}_i)\), which is small when \(\hat{p}_i\) is close to 0.
Comparing Loss Functions: Logistic vs. Linear Regression
Both linear and logistic regression fit into the same ML framework: define a loss function, then minimize it.
The choice of loss function depends on the problem: squared error makes sense for continuous outcomes, cross-entropy makes sense for probabilities.
Connection to statistics
In statistics, minimizing cross-entropy loss is equivalent to maximum likelihood estimation. Minimizing MSE is equivalent to maximum likelihood under the assumption that errors are normally distributed. Both approaches—ML and statistics—arrive at the same answer through different reasoning.
Logistic Regression for Credit Default
Let’s fit logistic regression to our credit default data:
from sklearn.linear_model import LogisticRegression# Fit logistic regressionlog_reg = LogisticRegression()log_reg.fit(X, y)# Predictionsprob_logistic = log_reg.predict_proba(balance_grid)[:, 1]print(f"Logistic Regression:")print(f" Intercept: {log_reg.intercept_[0]:.4f}")print(f" Coefficient on balance: {log_reg.coef_[0, 0]:.6f}")
Logistic Regression:
Intercept: -11.6163
Coefficient on balance: 0.006383
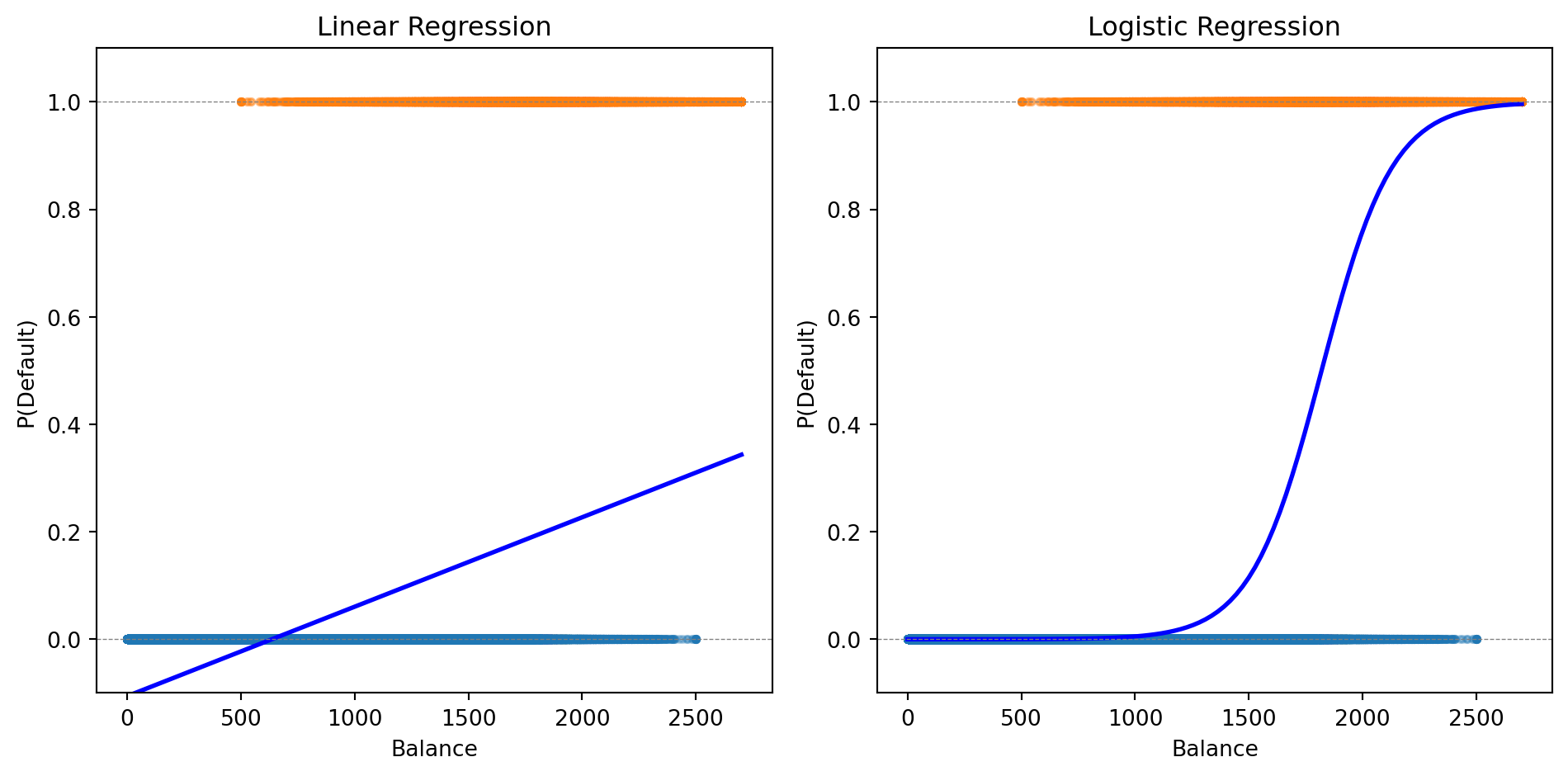
The logistic curve stays within [0, 1] and captures the S-shaped relationship between balance and default probability.
Making Predictions
Logistic regression gives us a probability. To make a classification decision, we need a threshold (also called a cutoff).
The default rule: predict class 1 if \(P(y = 1 \,|\, \mathbf{x}) > 0.5\)
# Fit with both balance and incomeX_both = np.column_stack([balance, income])log_reg_both = LogisticRegression()log_reg_both.fit(X_both, default)print(f"Logistic Regression with Balance and Income:")print(f" Intercept: {log_reg_both.intercept_[0]:.4f}")print(f" Coefficient on balance: {log_reg_both.coef_[0, 0]:.6f}")print(f" Coefficient on income: {log_reg_both.coef_[0, 1]:.9f}")
Logistic Regression with Balance and Income:
Intercept: -11.2532
Coefficient on balance: 0.006383
Coefficient on income: -0.000009279
The coefficient on income is tiny—income adds little predictive power beyond balance.
Multi-Class Logistic Regression
When we have \(K > 2\) classes, we can extend logistic regression using the softmax function.
For each class \(k\), we define a linear predictor:
The penalty \(\lambda \sum |\beta_j|\) shrinks coefficients toward zero and can set some exactly to zero (variable selection).
Benefits:
Prevents overfitting when \(p\) is large relative to \(n\)
Identifies which features matter most
Improves out-of-sample prediction
The regularization parameter \(\lambda\) is chosen by cross-validation.
from sklearn.linear_model import LogisticRegressionCV# Fit Lasso logistic regression with CVlog_reg_lasso = LogisticRegressionCV(penalty='l1', solver='saga', cv=5, max_iter=1000)log_reg_lasso.fit(X_both, default)print(f"Lasso Logistic Regression (λ chosen by CV):")print(f" Best C (inverse of λ): {log_reg_lasso.C_[0]:.4f}")print(f" Coefficient on balance: {log_reg_lasso.coef_[0, 0]:.6f}")print(f" Coefficient on income: {log_reg_lasso.coef_[0, 1]:.9f}")
Lasso Logistic Regression (λ chosen by CV):
Best C (inverse of λ): 0.0001
Coefficient on balance: 0.001064
Coefficient on income: -0.000123506
Part III: Decision Boundaries
The Decision Boundary
Think of a classifier as drawing a line (or curve) through feature space that separates the classes. The decision boundary is this dividing line—observations on one side get predicted as Class 0, observations on the other side as Class 1.
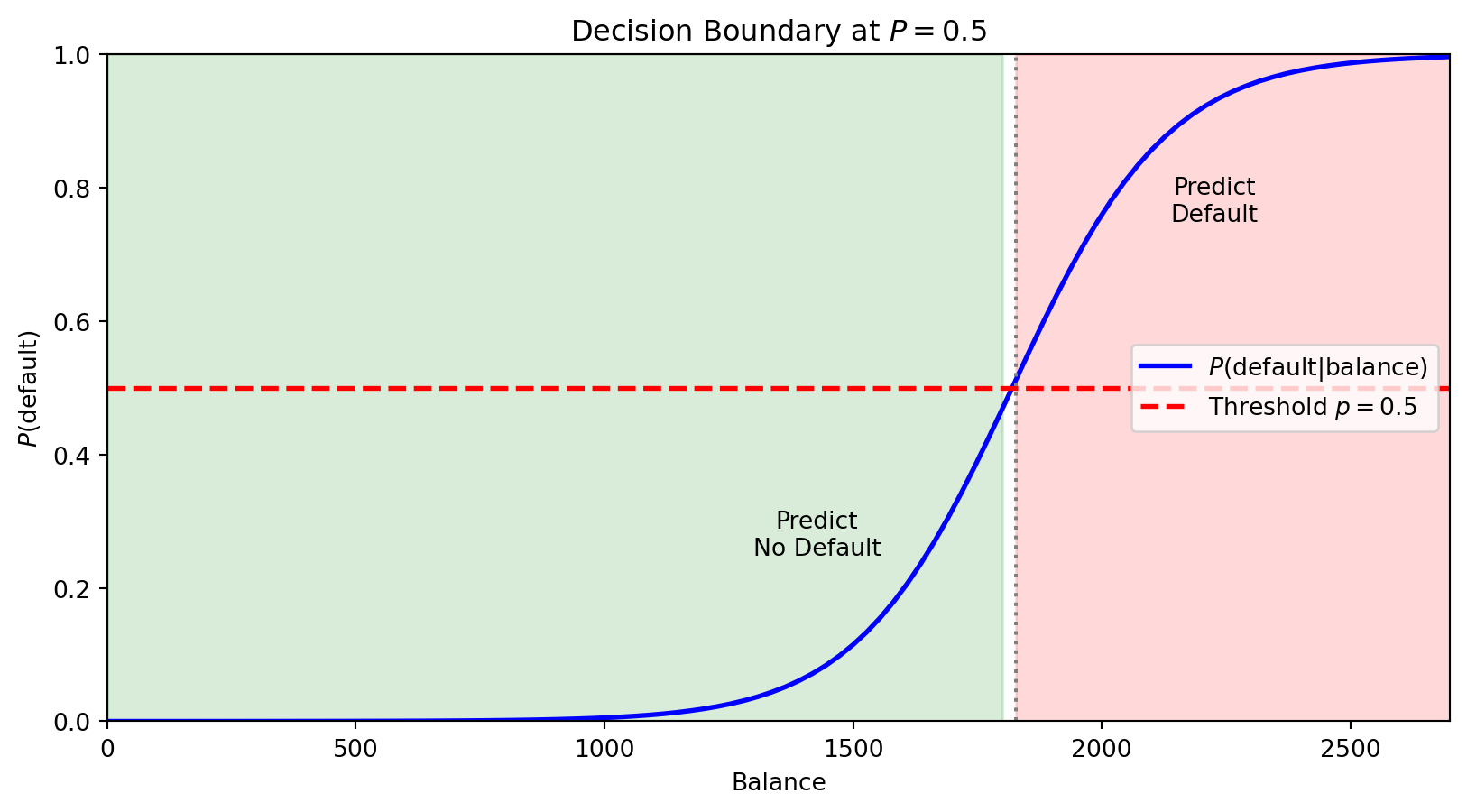
For logistic regression with threshold 0.5, we predict Class 1 when \(P(y = 1 \,|\, \mathbf{x}) > 0.5\).
The boundary is where \(P(y = 1 \,|\, \mathbf{x}) = 0.5\) exactly—the point of maximum uncertainty.
The horizontal red line marks \(P = 0.5\). Where the probability curve crosses this threshold defines the decision boundary in feature space—observations with balance above this point are predicted to default.
With multiple features, the boundary is where \(\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots = 0\)—a linear equation in the features. This is why logistic regression is called a linear classifier: the decision boundary is a line (in 2D) or hyperplane (in higher dimensions).
What If Classes Aren’t Linearly Separable?
Sometimes a straight line can’t separate the classes well. We can create curved boundaries by adding transformed features to our model:
Include \(x_1^2\), \(x_2^2\), \(x_1 x_2\) as additional features
The model is still logistic regression (linear in these new features)
But the boundary is now curved in the original \((x_1, x_2)\) space
We’ll see more flexible classifiers (trees, k-NN) next week that don’t require manual feature engineering.
The model is still “logistic regression” (linear in the transformed features), but the decision boundary is nonlinear in the original features.
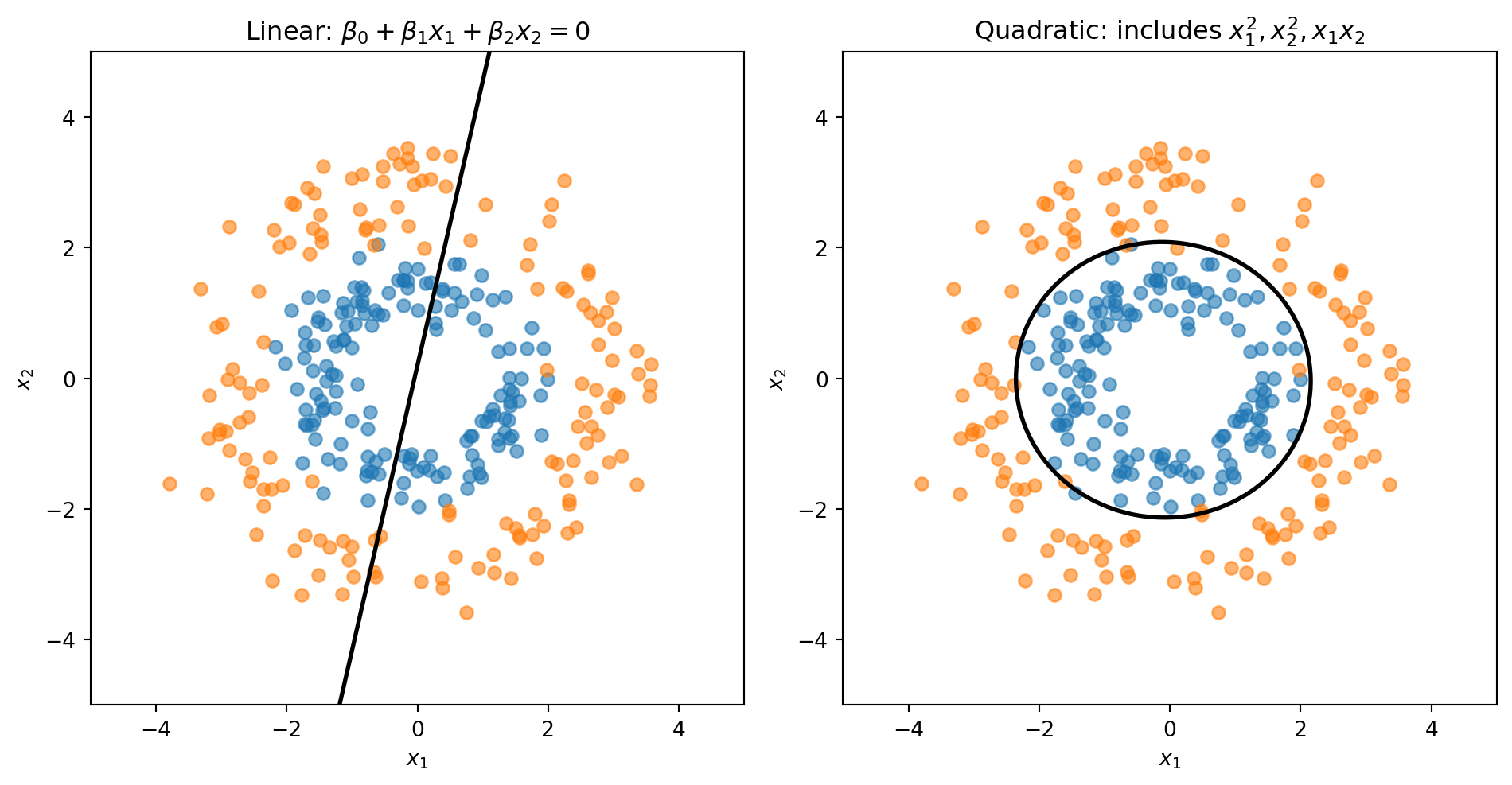
Linear vs. Quadratic Boundaries
Consider data where Class 0 forms an inner ring and Class 1 forms an outer ring. No straight line can separate these classes—we need a circular boundary.
A circle centered at the origin has equation \(x_1^2 + x_2^2 = r^2\). If we add squared terms as features, the decision boundary becomes:
This is a quadratic equation in \(x_1\) and \(x_2\)—it can represent circles, ellipses, or other curved shapes.
from sklearn.preprocessing import PolynomialFeatures# Linear: uses only x1, x2log_reg_linear = LogisticRegression()log_reg_linear.fit(X_ring, y_ring)# Quadratic: add x1^2, x2^2, x1*x2 as new featurespoly = PolynomialFeatures(degree=2)X_ring_poly = poly.fit_transform(X_ring)log_reg_quad = LogisticRegression()log_reg_quad.fit(X_ring_poly, y_ring)
LogisticRegression()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
The linear model is forced to draw a straight line through the rings. The quadratic model can learn a circular boundary that actually separates the classes.
Part IV: Linear Discriminant Analysis
Why Another Classifier?
Clustering (Week 5)
Logistic Regression
LDA
Type
Unsupervised
Supervised
Supervised
Labels
Unknown — discover them
Known — learn a boundary
Known — learn distributions
Strategy
Assume each group is a distribution; find the groups
Directly model \(P(y \mid \mathbf{x})\)
Model \(P(\mathbf{x} \mid y)\) per class, then apply Bayes’ theorem
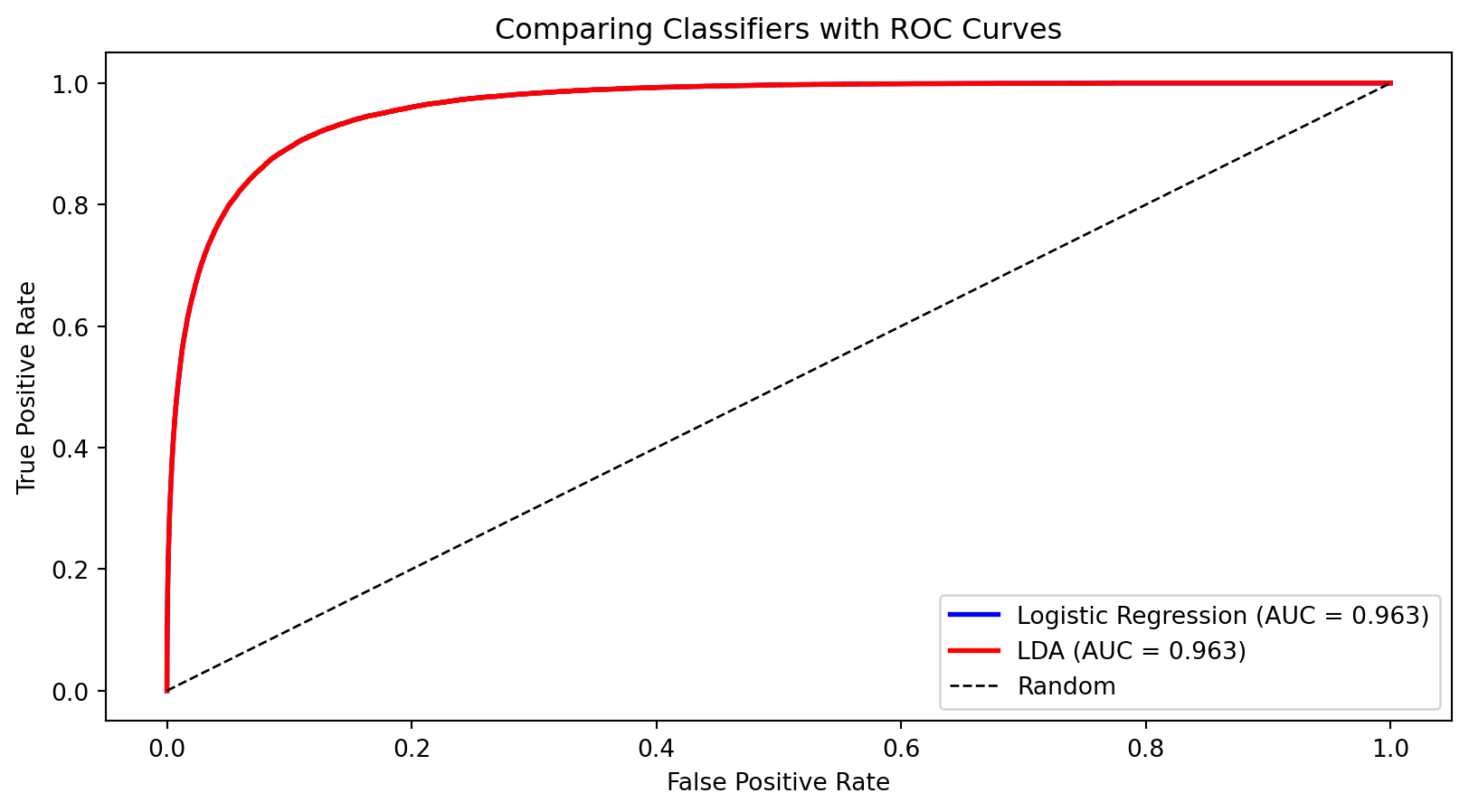
LDA is the supervised version of the distributional thinking you used in clustering: instead of discovering groups, you already know them and want to learn what makes each group different.
In practice, LDA and logistic regression often give similar answers — the value is in understanding both ways of thinking about classification.
A Different Approach: Bayes’ Theorem
Logistic regression directly models \(P(y | \mathbf{x})\)—the probability of the class given the features.
Discriminant analysis takes a different approach using Bayes’ theorem:
\[P(y = k | \mathbf{x}) = \frac{P(\mathbf{x} | y = k) \cdot P(y = k)}{P(\mathbf{x})}\]
\(\boldsymbol{\mu}_k\) is the mean of class \(k\) (different for each class)
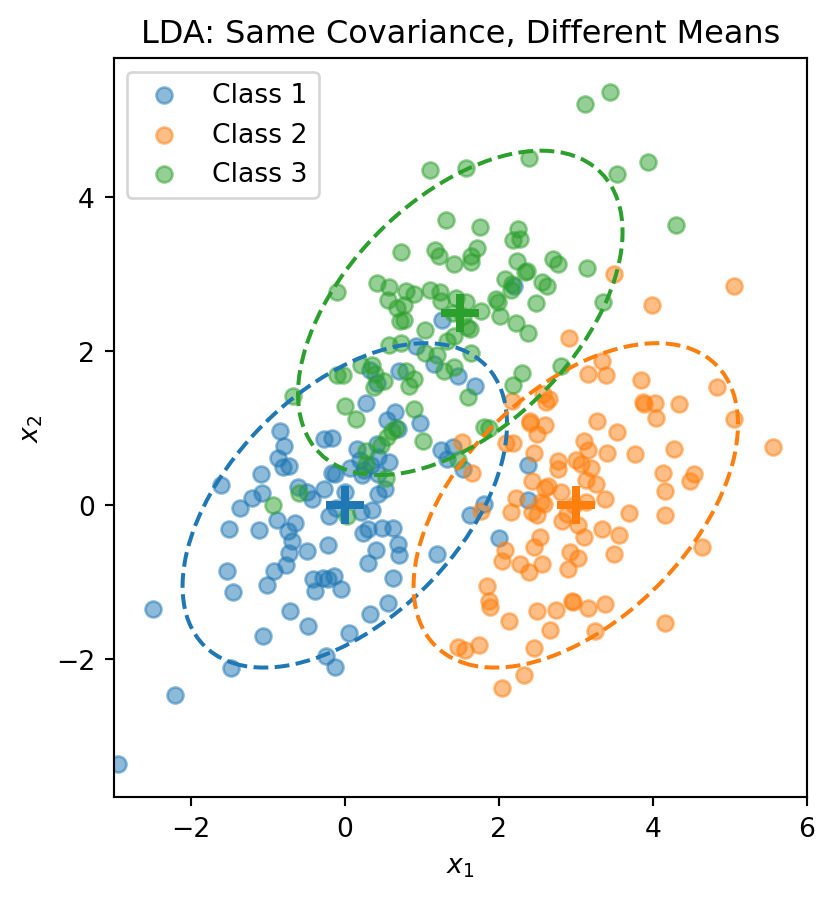
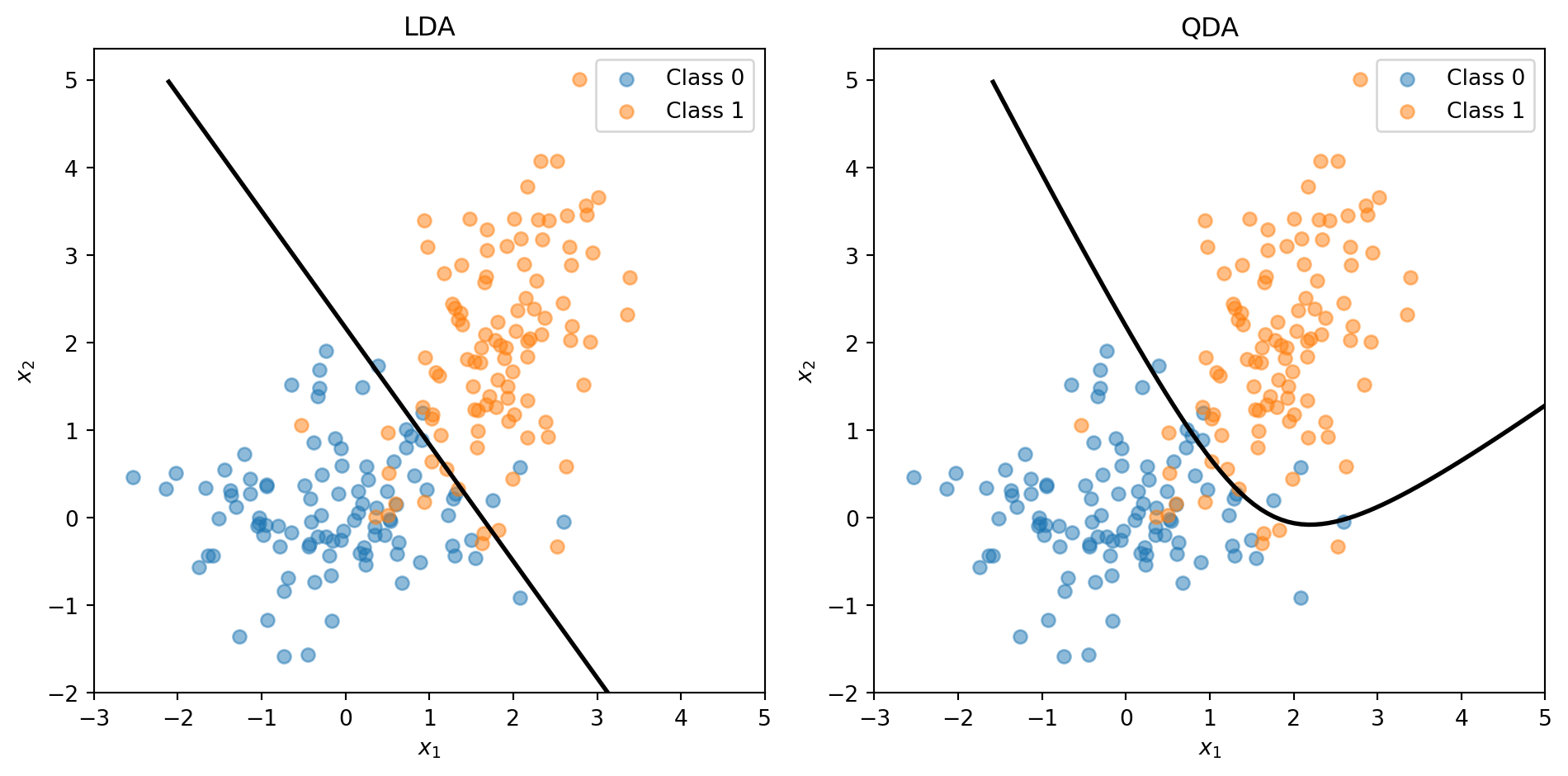
\(\boldsymbol{\Sigma}\) is the covariance matrix (same for all classes — this is the key assumption!)
Each class is a normal “blob” centered at \(\boldsymbol{\mu}_k\), but all classes share the same shape (covariance).
Visualizing the LDA Assumption
The dashed ellipses show the 95% probability contours—they have the same shape (orientation and spread) but different centers.
The LDA Discriminant Function
Start with the posterior from Bayes’ theorem:
\[P(y = k \,|\, \mathbf{x}) = \frac{f_k(\mathbf{x}) \pi_k}{\sum_{j=1}^{K} f_j(\mathbf{x}) \pi_j}\]
Taking the log and plugging in the normal density:
\[\ln P(y = k \,|\, \mathbf{x}) = \ln f_k(\mathbf{x}) + \ln \pi_k - \underbrace{\ln \sum_{j} f_j(\mathbf{x}) \pi_j}_{\text{same for all } k}\]
The normal density gives \(\ln f_k(\mathbf{x}) = -\frac{p}{2}\ln(2\pi) - \frac{1}{2}\ln|\boldsymbol{\Sigma}| - \frac{1}{2}(\mathbf{x} - \boldsymbol{\mu}_k)'\boldsymbol{\Sigma}^{-1}(\mathbf{x} - \boldsymbol{\mu}_k)\).
The first two terms don’t depend on \(k\) (shared covariance!). Expanding the quadratic and dropping terms that don’t depend on \(k\), we get the discriminant function:
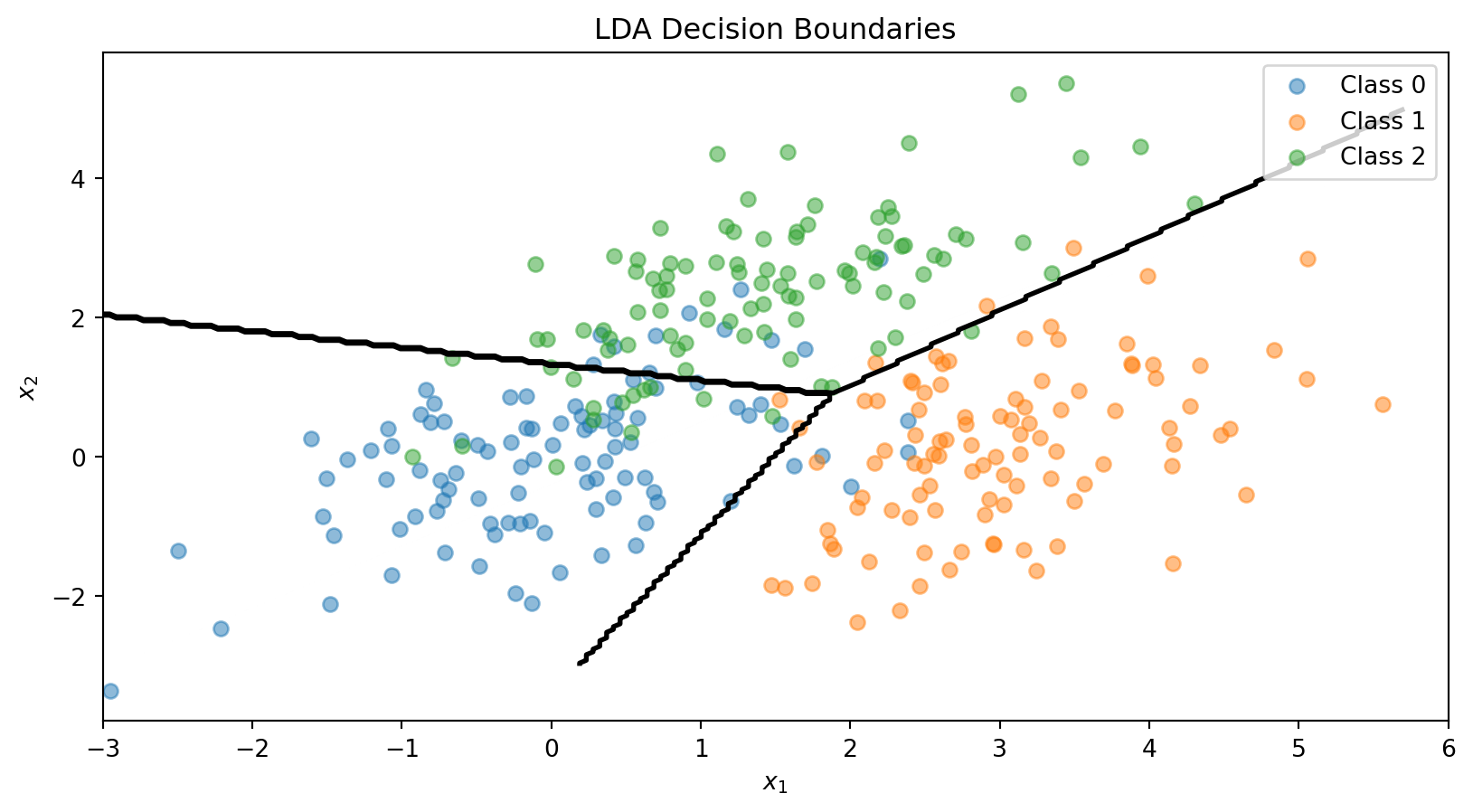
This is a scalar—one number for each class \(k\). We classify \(\mathbf{x}\) to the class with the largest discriminant: \(\hat{y} = \arg\max_k \delta_k(\mathbf{x})\).
The discriminant function is linear in \(\mathbf{x}\)—that’s why it’s called Linear Discriminant Analysis.
The LDA Decision Boundary
The decision boundary between classes \(k\) and \(\ell\) is where:
The pooled covariance averages within-class covariances, weighted by class size.
The LDA Recipe
LDA
Model
Each class \(k\) is a multivariate normal: \(\mathbf{x} \mid y = k \;\sim\; \mathcal{N}(\boldsymbol{\mu}_k,\, \boldsymbol{\Sigma})\)
Parameters
Priors \(\hat{\pi}_k = n_k / n\), means \(\hat{\boldsymbol{\mu}}_k\), pooled covariance \(\hat{\boldsymbol{\Sigma}}\)
“Loss function”
Not a loss function — parameters are estimated directly from the data (sample proportions, sample means, pooled covariance)
Classification rule
Assign \(\mathbf{x}\) to the class with the largest discriminant \(\delta_k(\mathbf{x})\)
No optimization loop, no gradient descent. LDA computes its parameters in closed form — plug in the training data and you’re done.
This is fundamentally different from logistic regression, which iteratively searches for the coefficients that minimize cross-entropy loss.
LDA in Python
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis# Combine the 3-class dataX_lda = np.vstack([X1, X2, X3])y_lda = np.array([0] * n_per_class + [1] * n_per_class + [2] * n_per_class)# Fit LDAlda = LinearDiscriminantAnalysis()lda.fit(X_lda, y_lda)print("LDA Class Means:")for k inrange(3):print(f" Class {k}: {lda.means_[k]}")print(f"\nClass Priors: {lda.priors_}")
LDA Class Means:
Class 0: [ 0.00962094 -0.02608294]
Class 1: [3.00835928 0.12294623]
Class 2: [1.40152169 2.3715806 ]
Class Priors: [0.33333333 0.33333333 0.33333333]
Precision: Of those we predicted positive, how many actually are? \[\text{Precision} = \frac{TP}{TP + FP}\]
Recall (Sensitivity): Of the actual positives, how many did we catch? \[\text{Recall} = \frac{TP}{TP + FN}\]
Specificity: Of the actual negatives, how many did we correctly identify? \[\text{Specificity} = \frac{TN}{TN + FP}\]
False Positive Rate: Of actual negatives, how many did we wrongly call positive? \[\text{FPR} = \frac{FP}{TN + FP} = 1 - \text{Specificity}\]
Credit Default: Confusion Matrix
from sklearn.metrics import confusion_matrix, classification_report# Using our credit default data with logistic regressiony_pred = log_reg.predict(X)# Confusion matrixcm = confusion_matrix(default, y_pred)print("Confusion Matrix:")print(f" Predicted No Predicted Yes")print(f" Actual No {cm[0,0]:5d}{cm[0,1]:5d}")print(f" Actual Yes {cm[1,0]:5d}{cm[1,1]:5d}")
Confusion Matrix:
Predicted No Predicted Yes
Actual No 961793 5207
Actual Yes 19202 13798
Lowering the threshold from 0.5 to 0.1 dramatically increases recall (catching defaults) at the cost of more false positives.
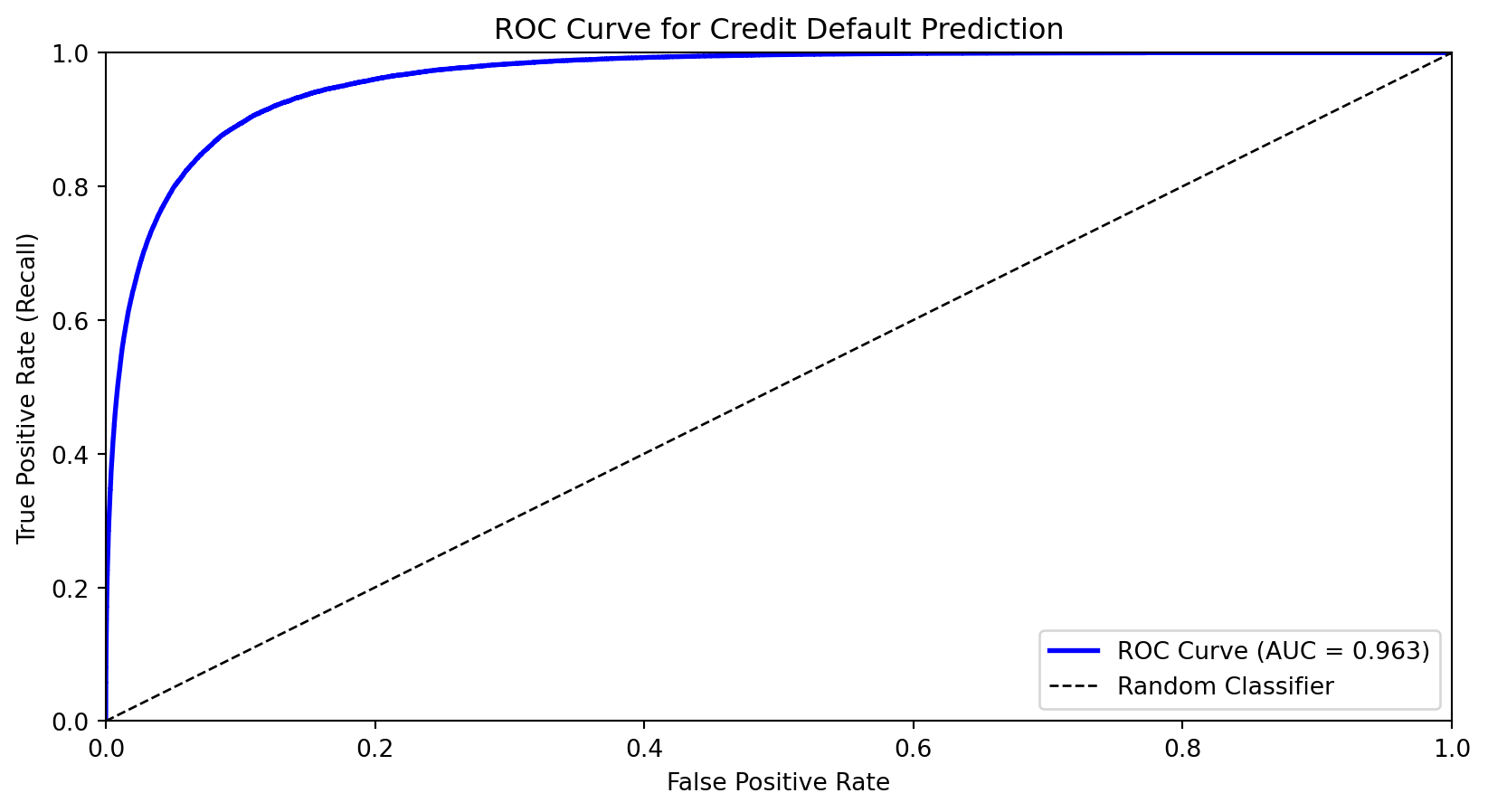
The ROC Curve
The Receiver Operating Characteristic (ROC) curve shows the trade-off between true positive rate (recall) and false positive rate across all thresholds.
X-axis: False Positive Rate (FPR)
Y-axis: True Positive Rate (TPR = Recall)
As we lower the threshold:
We move from bottom-left (predict nothing positive) toward top-right (predict everything positive)
Good classifiers hug the top-left corner
Area Under the ROC Curve (AUC)
The Area Under the Curve (AUC) summarizes the ROC curve in a single number:
AUC = 1.0: Perfect classifier
AUC = 0.5: Random guessing (diagonal line)
AUC < 0.5: Worse than random (predictions inverted)
Interpretation: AUC is the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
from sklearn.metrics import roc_auc_scoreauc = roc_auc_score(default, prob_pred)print(f"AUC for credit default model: {auc:.3f}")
AUC for credit default model: 0.963
AUC is useful for comparing models because it’s threshold-independent—it measures the model’s ability to rank observations correctly.
Choosing the Optimal Threshold
The “best” threshold depends on the costs of different errors:
Cost of false negative (missing a default): \(c_{FN}\)
Cost of false positive (false alarm): \(c_{FP}\)
If missing defaults is very costly (e.g., the bank loses the loan amount), we want a lower threshold to maximize recall.
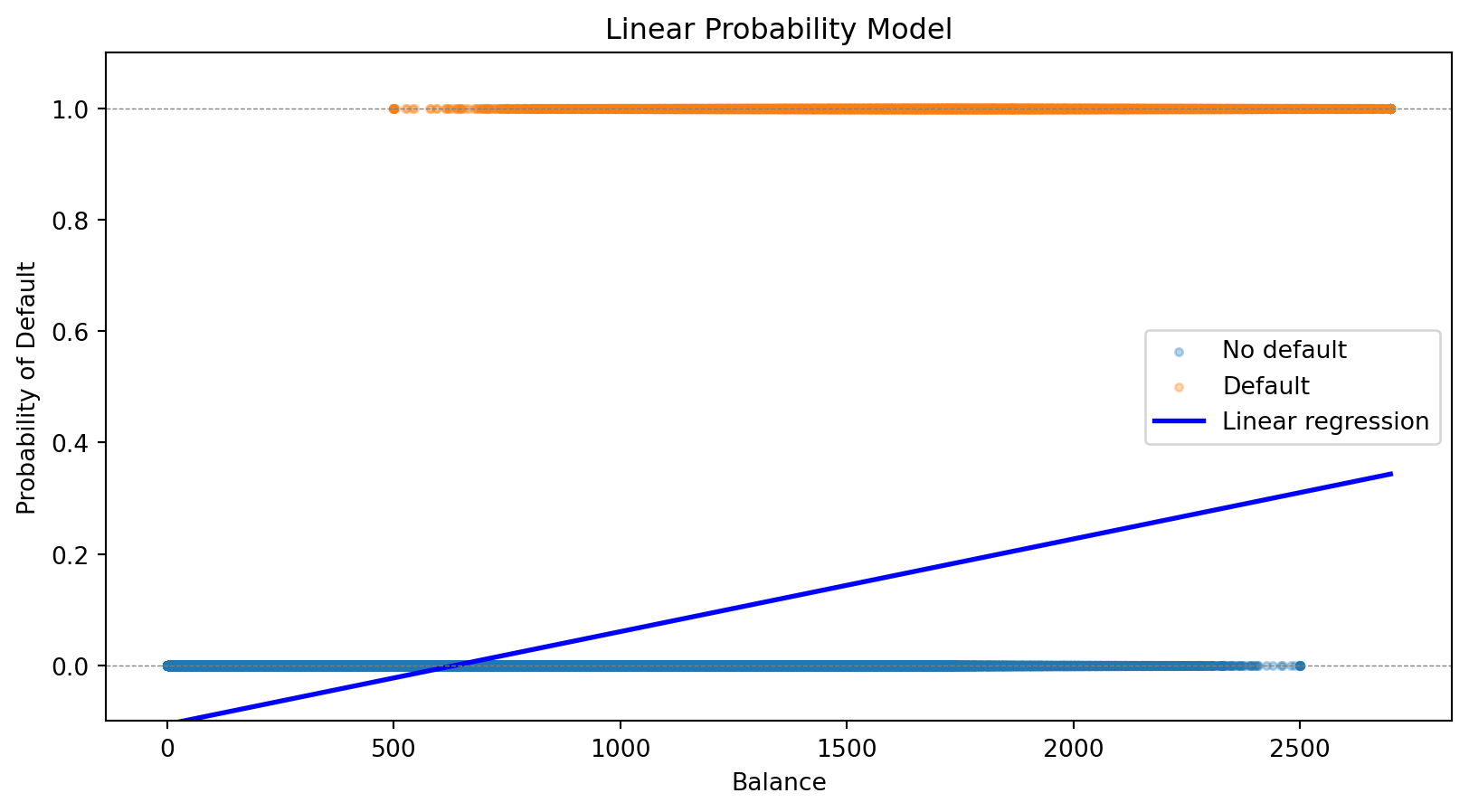
Linear probability model (regression with 0/1 outcome) fails because it can produce impossible probabilities.
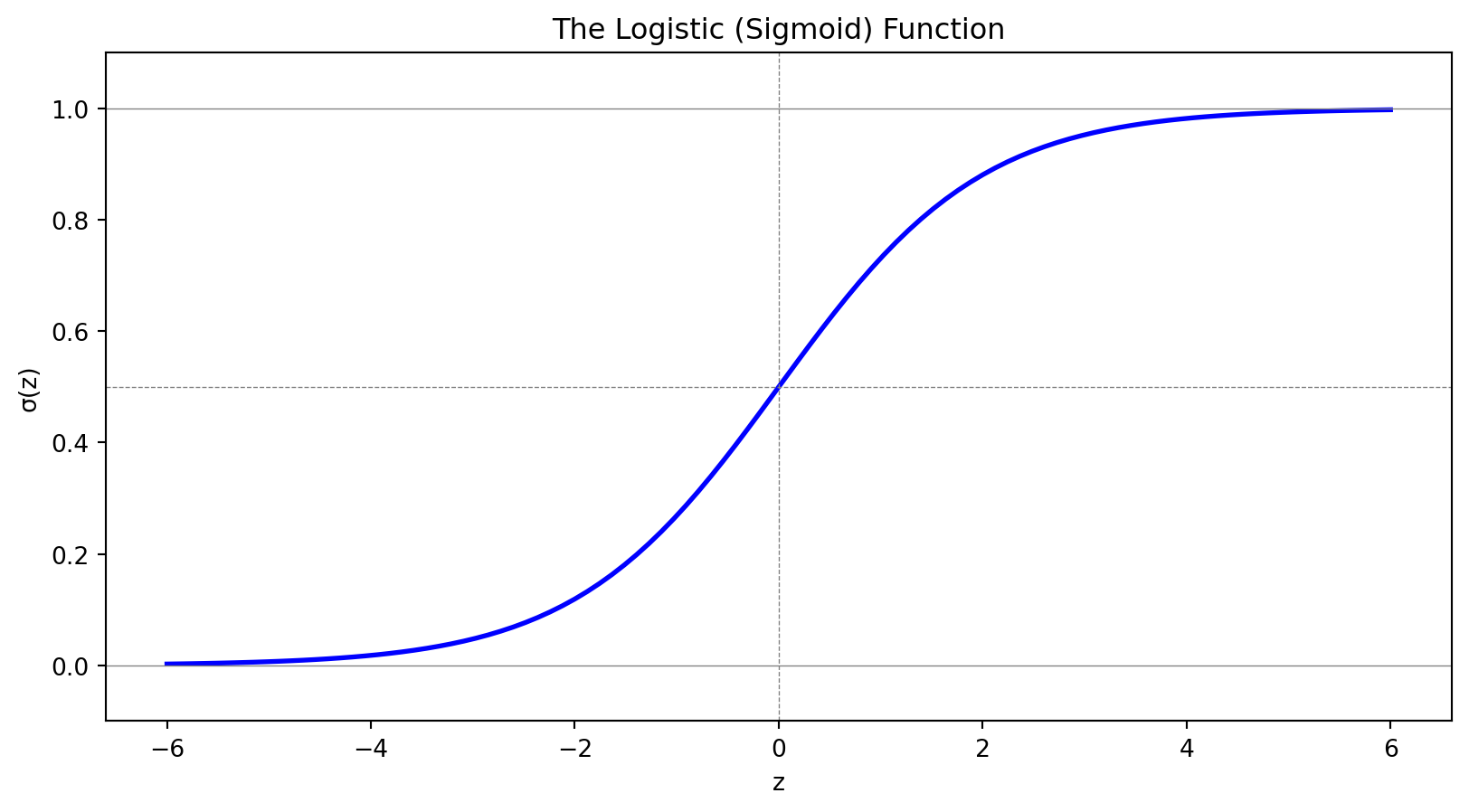
Logistic regression uses the sigmoid function to model probabilities properly:
Outputs are always in (0, 1)
Coefficients measure effect on log-odds
Can be regularized (Lasso) for variable selection
Linear Discriminant Analysis takes a Bayesian approach:
Models class-conditional distributions as normal
Assumes shared covariance (LDA) or class-specific covariance (QDA)
Often performs similarly to logistic regression
Evaluation Metrics
Accuracy can be misleading with imbalanced classes.
The confusion matrix breaks down predictions into TP, FP, TN, FN.
Precision (of predicted positives, how many are correct?) and Recall (of actual positives, how many did we catch?) capture different aspects of performance.
The ROC curve shows the trade-off across all thresholds.
AUC summarizes discriminative ability in a single number.
The optimal threshold depends on the costs of different types of errors.
Next Week
Week 8: Nonlinear Classification
We’ll extend to methods that create nonlinear decision boundaries:
k-Nearest Neighbors (k-NN): Classify based on nearby training points
Decision Trees: Recursive partitioning of feature space
Support Vector Machines: Find the maximum margin boundary
These methods can capture complex patterns that linear classifiers miss.
References
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2), 179-188.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer. Chapter 4.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning (2nd ed.). Springer. Chapter 4.