We often want to annualize multi-year returns for comparison.
Suppose you observe a \(T\)-year cumulative return \(R_{1 \to T}\). What’s the annualized return?
You need the \(\bar{R}\) such that earning \(\bar{R}\) each year gives the same cumulative return:
\[(1 + \bar{R})^T = 1 + R_{1 \to T}\]
Solving:
\[\bar{R} = (1 + R_{1 \to T})^{1/T} - 1\]
The problem: This \((\cdot)^{1/T}\) operation is a nonlinear function of returns, and recall that \(\mathbb{E}[f(X)] \neq f(\mathbb{E}[X])\) in general.
The average of annualized returns \(\neq\) annualized average return
Variances don’t scale nicely
Taking roots of random variables creates bias
With log returns, annualization is just division by \(T\). Much cleaner.
Log Returns (Continuously Compounded Returns)
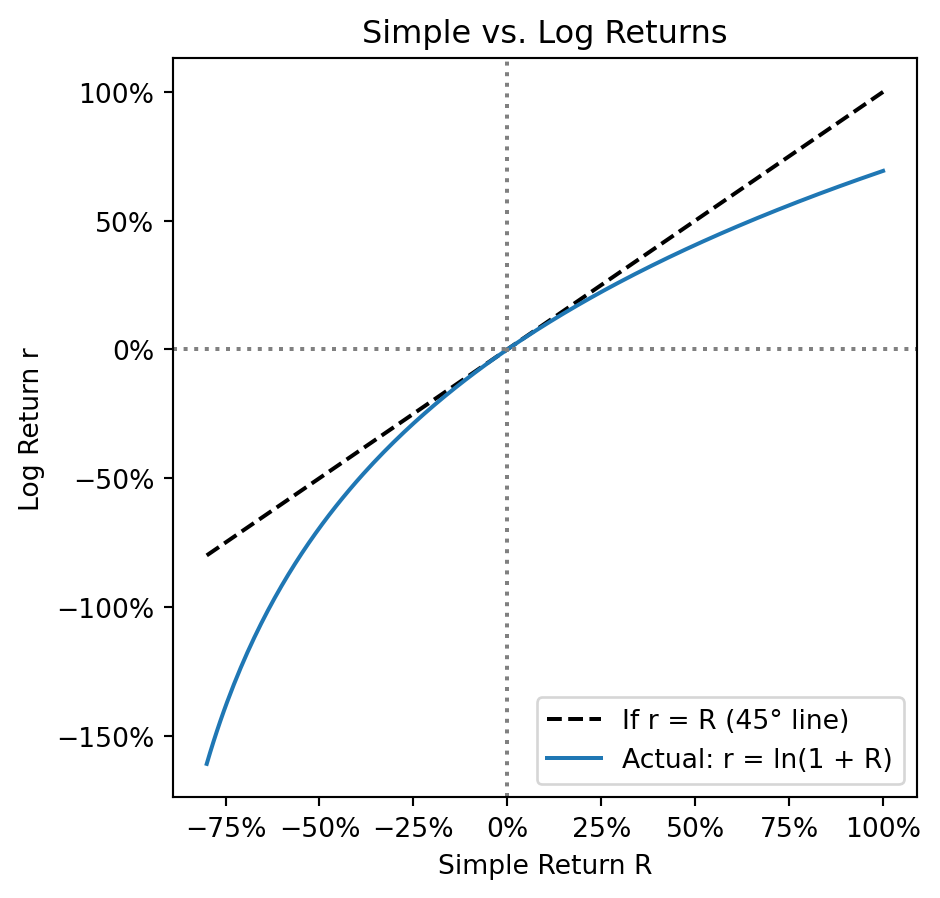
Given a simple return \(R\), what is the equivalent continuously compounded return \(r\)?
By definition, \(r\) is the rate such that continuous compounding gives the same growth:
\[e^r = 1 + R\]
Solving for \(r\):
\[r = \ln(1 + R)\]
This is why they’re called log returns—they’re literally the logarithm of gross returns.
For stocks (ignoring dividends), the gross return is \(1 + R_t = \frac{P_t}{P_{t-1}}\), so:
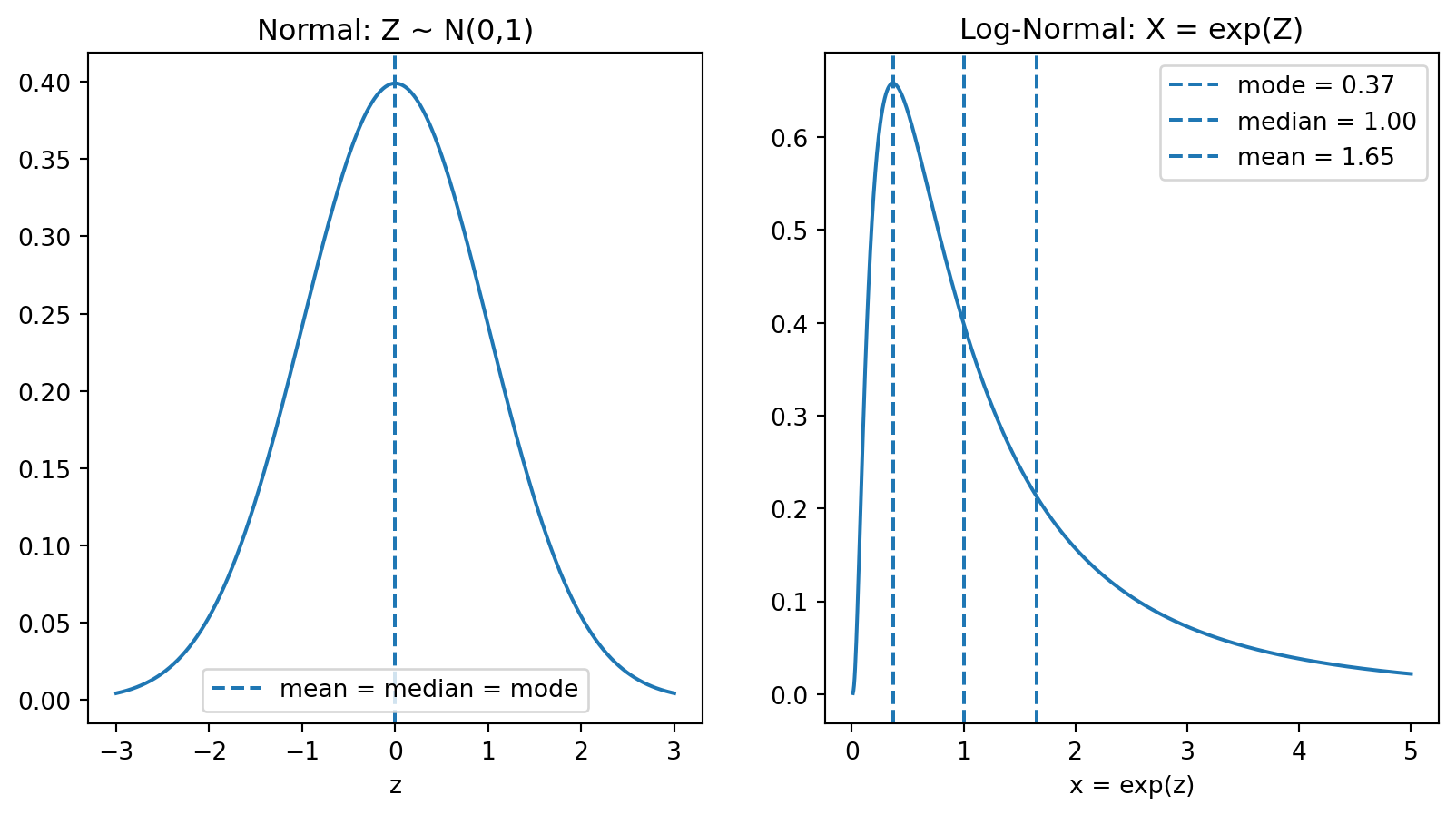
The \(\frac{\sigma^2}{2}\) term is the variance boost. The more spread out \(Z\) is (higher variance), the more the exponential “boosts” the high values relative to the low values.
Expected Wealth After \(T\) Years
Recall: our “naïve” forecast for terminal wealth (ignoring variance) was \(W_0 \cdot e^{T\mu}\).
But now we know the true expected value includes the variance boost:
The factor \(e^{T\sigma^2/2}\) is the variance boost:
It grows with time horizon\(T\): longer investments have larger boosts
It grows with volatility\(\sigma^2\): riskier assets have larger boosts
This happens because wealth is log-normally distributed with a fat right tail: Mean \(>\) Median, and the gap widens with \(T\) and \(\sigma^2\)
Over long horizons, expected wealth becomes much larger than what a “typical” investor will experience
Simulating 100,000 Investors
Step 0: Estimate \(\mu\) and \(\sigma\) from real data.
Rather than using made-up numbers, let’s estimate from actual S&P 500 history.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom scipy import statsimport os# Load S&P 500 data (download if not cached locally)csv_path ='sp500_yf.csv'if os.path.exists(csv_path): sp500 = pd.read_csv(csv_path, index_col='Date', parse_dates=True)else:import yfinance as yf sp500 = yf.download('^GSPC', start='1950-01-01', end='2025-12-31', progress=False) sp500.columns = sp500.columns.get_level_values(0) sp500.to_csv(csv_path)# Use the last 60 years of dataT =60# Investment horizon (years)end_year = sp500.index.max().yearstart_year = end_year - Tsp500_recent = sp500[sp500.index.year >= start_year]print(f"Using data from {start_year} to {end_year} ({T} years)")# Compute daily log returnsdaily_log_returns = np.log(sp500_recent['Close'] / sp500_recent['Close'].shift(1)).dropna()# Estimate daily mu and sigma, then annualize# (252 trading days per year)mu_daily = daily_log_returns.mean()sigma_daily = daily_log_returns.std()mu = mu_daily *252# Annualized meansigma = sigma_daily * np.sqrt(252) # Annualized volatilityprint(f"\nDaily estimates:")print(f" μ_daily: {mu_daily:.4%} σ_daily: {sigma_daily:.4%}")print(f"\nAnnualized (×252 for μ, ×√252 for σ):")print(f" μ (mean annual log return): {mu:.2%}")print(f" σ (annual volatility): {sigma:.2%}")
Using data from 1965 to 2025 (60 years)
Daily estimates:
μ_daily: 0.0286% σ_daily: 1.0555%
Annualized (×252 for μ, ×√252 for σ):
μ (mean annual log return): 7.22%
σ (annual volatility): 16.76%
Now we can compute forecasts:
Median (naïve forecast):\(e^{T\mu}\) — what you get if returns equal their mean every year
Mean (true expected value):\(e^{T\mu + T\sigma^2/2}\) — includes the variance boost
W_0 =1# Starting wealth = $1median_wealth = W_0 * np.exp(T * mu)mean_wealth = W_0 * np.exp(T * mu + T * sigma**2/2)print(f"Starting wealth: ${W_0}")print(f"Horizon: {T} years")print(f"\nMedian terminal wealth (naïve): ${median_wealth:,.0f}")print(f"Mean terminal wealth (true E[W]): ${mean_wealth:,.0f}")print(f"\nThe mean is {mean_wealth/median_wealth:.1f}× higher than the median!")
Starting wealth: $1
Horizon: 60 years
Median terminal wealth (naïve): $76
Mean terminal wealth (true E[W]): $177
The mean is 2.3× higher than the median!
The mean is pulled up by a small number of extremely lucky outcomes—most investors will earn less than the expected value. Let’s simulate this.
np.random.seed(42)n_investors =100000# Step 1: Draw 60 years of log returns for each investor# Each row = one investor, each column = one yearreturns = np.random.normal(mu, sigma, (n_investors, T))print(f"Shape: {returns.shape} (100,000 investors × {T} years)")print(f"First investor's first 5 years: {returns[0, :5].round(3)}")
Shape: (100000, 60) (100,000 investors × 60 years)
First investor's first 5 years: [0.155 0.049 0.181 0.327 0.033]
Each investor gets 60 independent draws from \(N(\mu, \sigma^2)\).
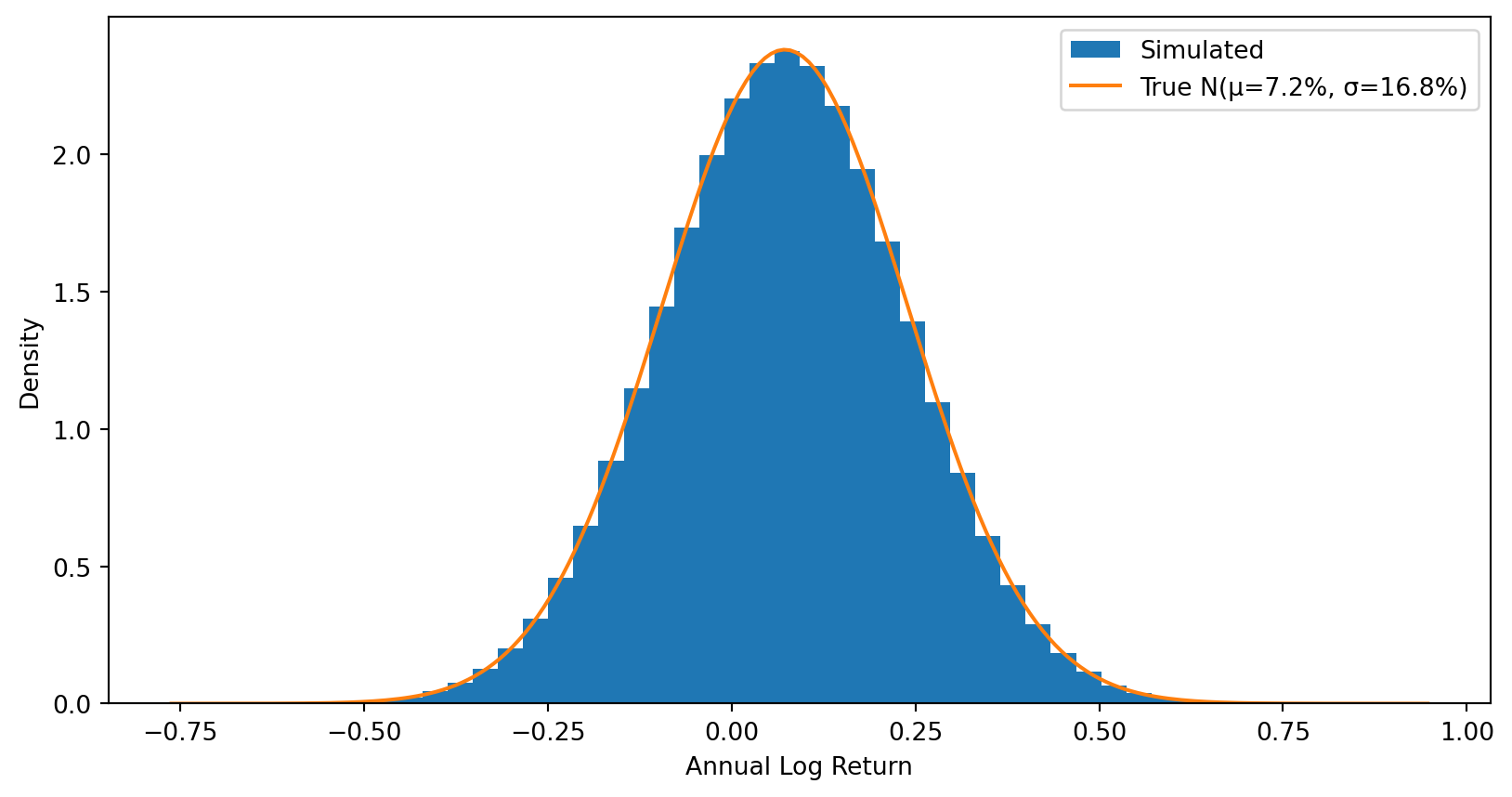
Step 1: Individual annual returns are normally distributed (symmetric).
# The distribution of individual annual returnsall_returns = returns.flatten()plt.hist(all_returns, bins=50, density=True, label='Simulated')# Overlay the true normal distributionx = np.linspace(all_returns.min(), all_returns.max(), 200)plt.plot(x, stats.norm.pdf(x, mu, sigma), label=f'True N(μ={mu:.1%}, σ={sigma:.1%})')plt.xlabel('Annual Log Return')plt.ylabel('Density')plt.legend()plt.show()
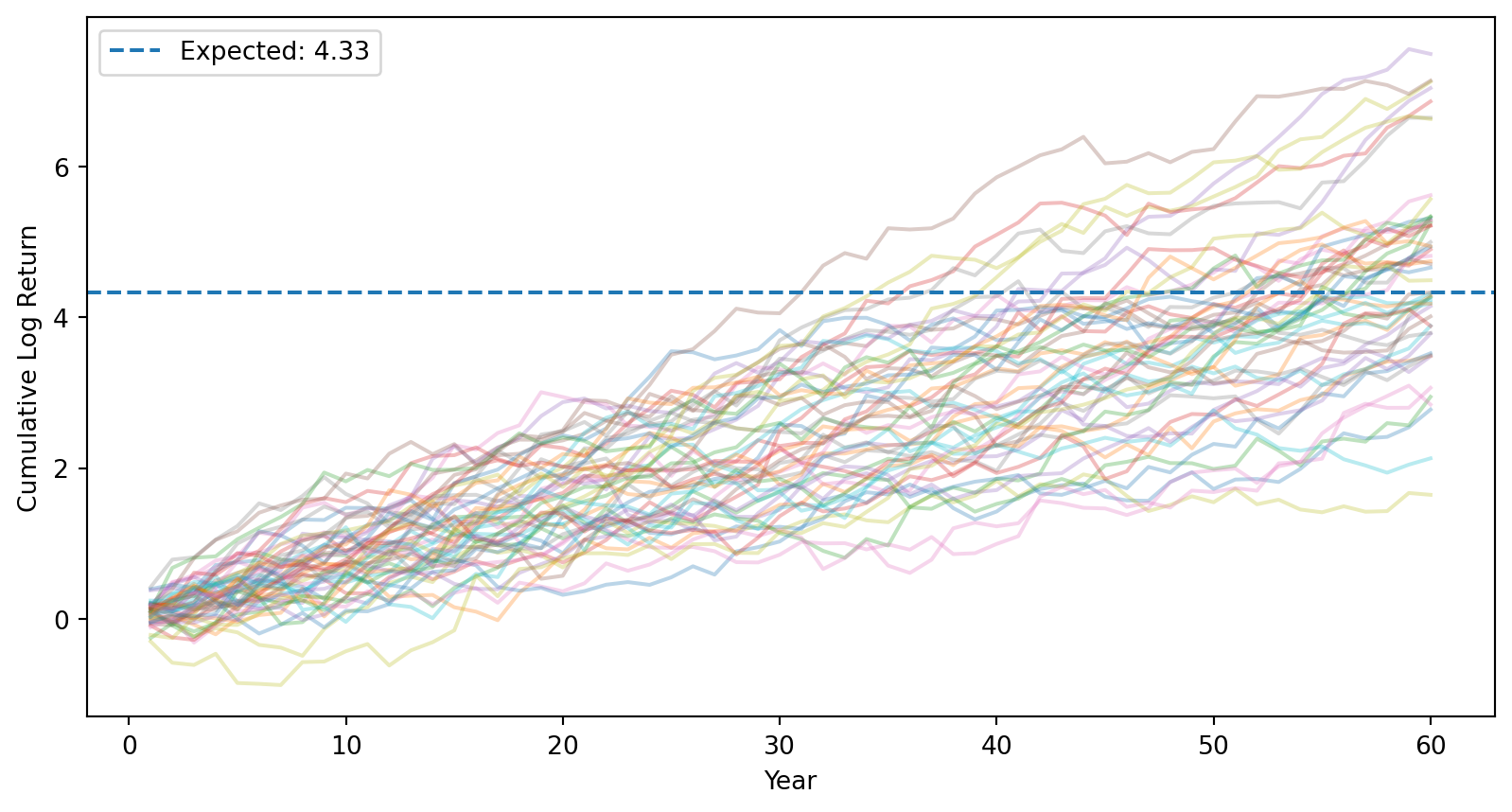
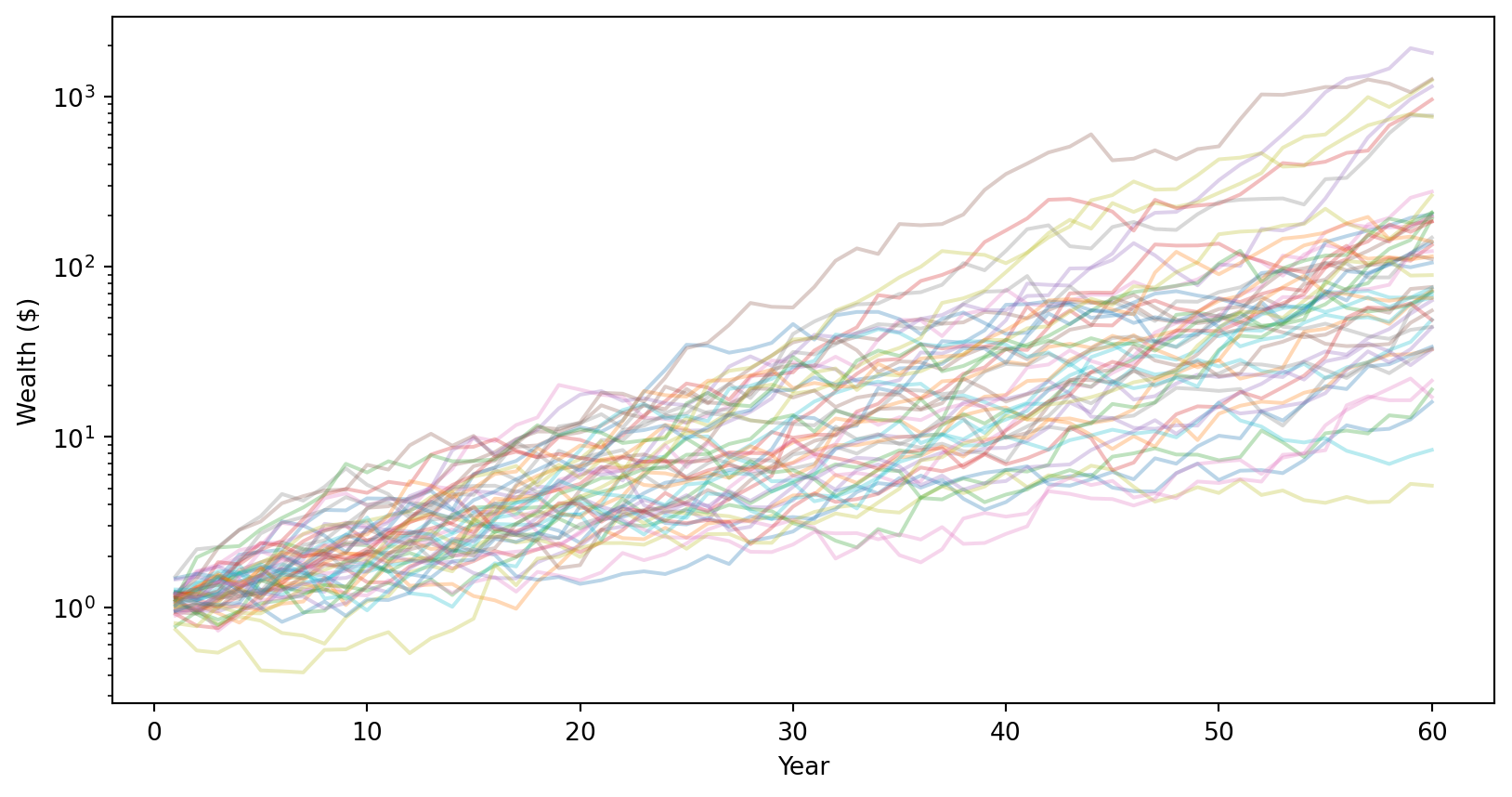
Step 2: Log returns accumulate over time (still symmetric).
# Cumulative log returns (running sum over time)cumulative_log_returns = np.cumsum(returns, axis=1)# Plot sample paths for a few investorsfor i inrange(50): plt.plot(range(1, T+1), cumulative_log_returns[i], alpha=0.3)plt.axhline(mu * T, linestyle='--', label=f'Expected: {mu*T:.2f}')plt.xlabel('Year')plt.ylabel('Cumulative Log Return')plt.legend()plt.show()
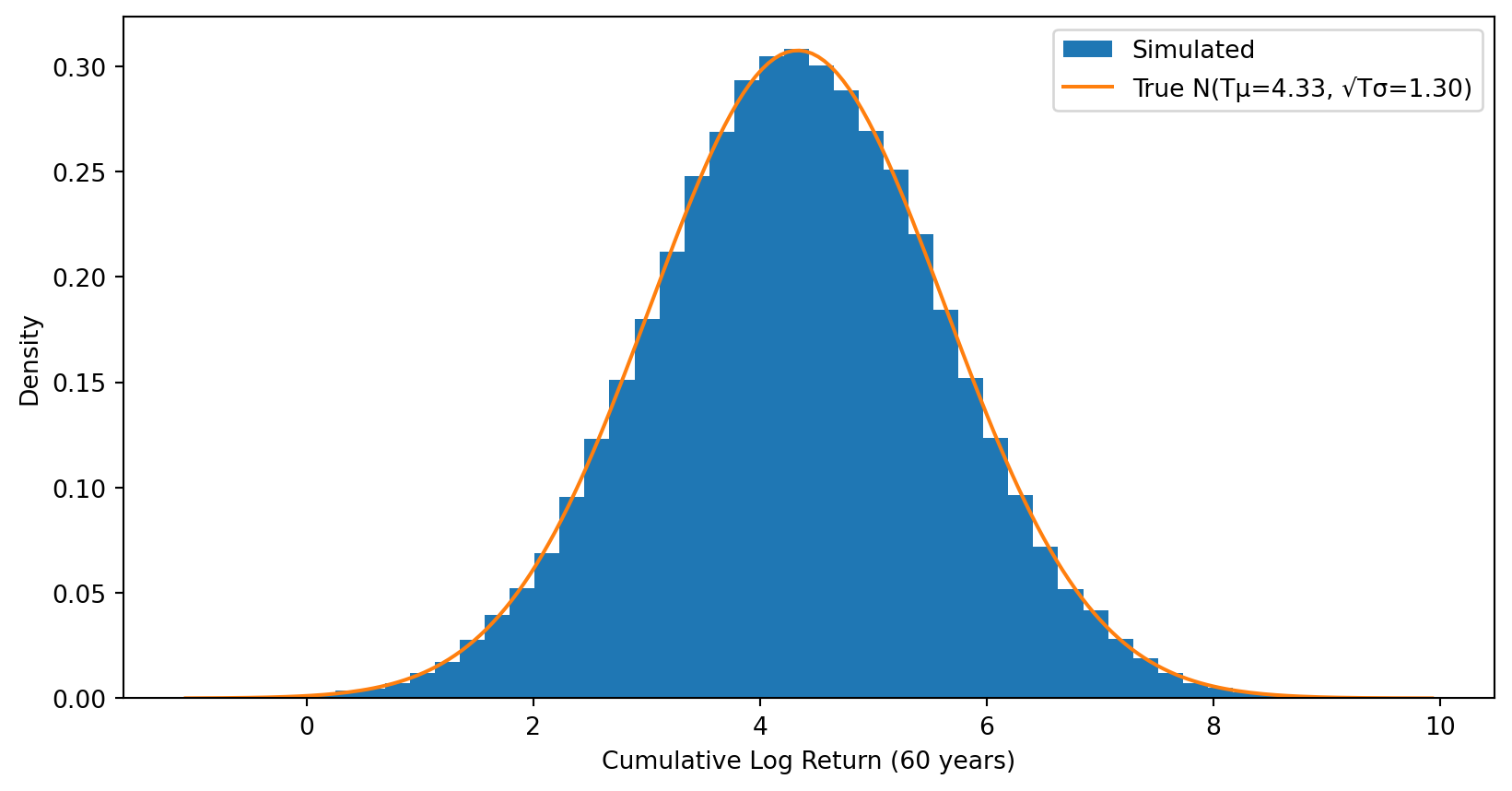
After \(T\) years, cumulative log return \(\sim N(T\mu, T\sigma^2)\) — still symmetric.
# Distribution of terminal cumulative log returnsterminal_log_returns = cumulative_log_returns[:, -1]plt.hist(terminal_log_returns, bins=50, density=True, label='Simulated')# Overlay the true normal distribution: N(T*mu, T*sigma^2)x = np.linspace(terminal_log_returns.min(), terminal_log_returns.max(), 200)plt.plot(x, stats.norm.pdf(x, mu*T, sigma*np.sqrt(T)), label=f'True N(Tμ={mu*T:.2f}, √Tσ={sigma*np.sqrt(T):.2f})')plt.xlabel(f'Cumulative Log Return ({T} years)')plt.ylabel('Density')plt.legend()plt.show()
Step 3: Exponentiate to get wealth (now asymmetric!).
# Convert to wealth by exponentiating: W_T = W_0 * exp(cumulative log return)wealth_paths = W_0 * np.exp(cumulative_log_returns)# Plot sample pathsfor i inrange(50): plt.plot(range(1, T+1), wealth_paths[i], alpha=0.3)plt.xlabel('Year')plt.ylabel('Wealth ($)')plt.yscale('log') # Log scale to see all pathsplt.show()
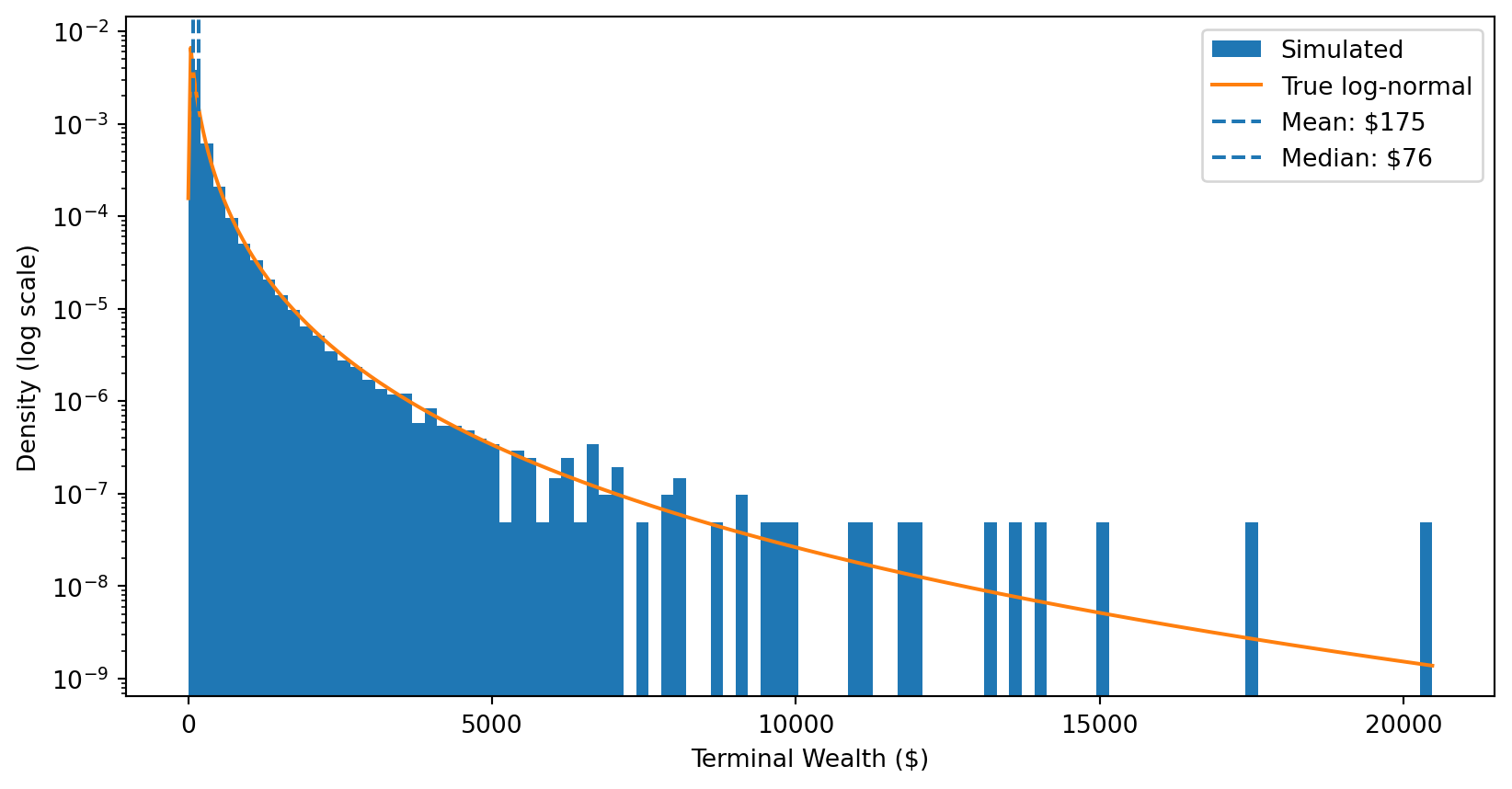
Step 4: Terminal wealth is log-normally distributed.
# Final wealth after T yearsterminal_wealth = wealth_paths[:, -1]plt.hist(terminal_wealth, bins=100, density=True, label='Simulated')# Overlay the true log-normal distribution# If ln(W) ~ N(m, v), then W is log-normal with scale=exp(m) and s=sqrt(v)x = np.linspace(terminal_wealth.min(), terminal_wealth.max(), 500)plt.plot(x, stats.lognorm.pdf(x, s=sigma*np.sqrt(T), scale=np.exp(mu*T)), label='True log-normal')plt.axvline(np.mean(terminal_wealth), linestyle='--', label=f'Mean: ${np.mean(terminal_wealth):.0f}')plt.axvline(np.median(terminal_wealth), linestyle='--', label=f'Median: ${np.median(terminal_wealth):.0f}')plt.xlabel('Terminal Wealth ($)')plt.ylabel('Density (log scale)')# plt.xscale('log')plt.yscale('log')plt.legend()plt.show()print(f"{100*np.mean(terminal_wealth < np.mean(terminal_wealth)):.0f}% of investors earn less than the mean!")
74% of investors earn less than the mean!
The punchline: Most investors earn less than the expected value!
The Punchline: Expected Value Is Biased Upward
Summary of Part I:
Log returns assumed normal \(\implies\) wealth is log-normal
The expected value of a log-normal includes a variance boost: \(e^{T\sigma^2/2}\)
This boost grows with time horizon \(T\) and volatility \(\sigma^2\)
As a result: Mean \(>\) Median \(>\) Mode for terminal wealth
The implication:
If you use expected wealth to plan for retirement (or advise clients), you will systematically overestimate what most people will actually experience.
Next: How do we adjust for this bias? And where does the uncertainty come from?
Part II: Estimation Risk
From Known to Unknown Parameters
In Part I, we treated \(\mu\) and \(\sigma^2\) as known parameters.
Reality: We don’t know the true expected return \(\mu\). We must estimate it from historical data.
This introduces estimation risk—additional uncertainty because our parameters are estimates, not truth.
Key question: If we plug our estimate \(\hat{\mu}\) into the wealth formula, do we get an unbiased forecast of expected wealth?
Spoiler: No. There’s an additional source of upward bias beyond what we saw in Part I.
What Is an Unbiased Estimator?
Definition: An estimator \(\hat{\theta}\) is unbiased if its expected value equals the true parameter:
\[\mathbb{E}[\hat{\theta}] = \theta\]
Example: The sample mean \(\bar{r} = \frac{1}{N}\sum_{i=1}^{N} r_i\) is an unbiased estimator of \(\mu\).
Why should we care?
Unbiased estimators are correct on average over repeated sampling
While \(\hat{\mu}\) is an unbiased estimator of \(\mu\), the wealth forecast \(\widehat{W}_T\) is not an unbiased estimator of \(\mathbb{E}[W_T]\)
The bias factor is \(\exp\left(\frac{T^2\sigma^2}{2N}\right)\)—it grows with \(T^2\)
We can correct for this bias by subtracting \(\frac{T^2\sigma^2}{2N}\) from the exponent
Estimation risk grows faster than return risk as horizon increases
Practical implication: Be skeptical of long-horizon wealth projections. They compound two sources of upward bias: the log-normal effect (Part I) and estimation error (Part II).
Part III: Testing the Normality Assumption
Are Returns Actually Normal?
Everything so far relied on one key assumption:
\[r_t \sim N(\mu, \sigma^2)\]
Is this actually true?
To investigate, we need tools to measure how a distribution deviates from normality:
Skewness: Is the distribution symmetric?
Kurtosis: How heavy are the tails?
For a normal distribution: skewness \(= 0\) and excess kurtosis \(= 0\).
Result: Overwhelming evidence against normality. Kurtosis \(\approx 25\) means extreme events are far more common than normal predicts.
Fat Tails: Extreme Events Happen More Than Expected
# Standardize daily returns (already computed above)daily_mu = daily_returns.mean()daily_sigma = daily_returns.std()standardized = (daily_returns - daily_mu) / daily_sigma# Count extreme eventsprint("Extreme events (beyond k standard deviations):\n")print(f"{'k-sigma':<10}{'Actual':<10}{'Normal predicts':<18}{'Ratio':<10}")print("-"*50)for k in [3, 4, 5, 6]: actual = (abs(standardized) > k).sum() expected =len(daily_returns) *2* stats.norm.sf(k) ratio = actual / expected if expected >0else np.inf# Use scientific notation for very small expected values exp_str =f"{expected:.1f}"if expected >=0.1elsef"{expected:.1e}"print(f"{k}-sigma {actual:<10}{exp_str:<18}{ratio:,.0f}x")# Worst dayworst_day = daily_returns.idxmin()worst_return = daily_returns.min()worst_sigma = (worst_return - daily_mu) / daily_sigmaprint(f"\nWorst day: {worst_day.strftime('%B %d, %Y')} (Black Monday)")print(f"Return: {worst_return:.1%}")print(f"That's {abs(worst_sigma):.0f} standard deviations from the mean!")
Extreme events (beyond k standard deviations):
k-sigma Actual Normal predicts Ratio
--------------------------------------------------
3-sigma 272 51.6 5x
4-sigma 107 1.2 88x
5-sigma 53 1.1e-02 4,837x
6-sigma 35 3.8e-05 928,055x
Worst day: October 19, 1987 (Black Monday)
Return: -22.9%
That's 23 standard deviations from the mean!
Key insight: The normal distribution dangerously underestimates tail risk. 4-sigma events happen ~90× more often than normality predicts.
What This Means for Practice
The normality assumption is an approximation.
Works reasonably well for “typical” days
Fails badly for extreme events (crashes, rallies)
Implications:
Risk management: VaR and other risk measures based on normality underestimate tail risk
In-sample: How well does the model fit the data used to estimate it?
Out-of-sample: How well does the model predict new data it hasn’t seen?
The problem: In-sample performance is overly optimistic.
Coefficients are “tuned” to fit the specific noise in the estimation sample
This is called overfitting—the model fits noise, not signal
Out-of-sample, the noise is different, so the fit degrades
This is why ML exists. Much of this course is about techniques to avoid overfitting and improve out-of-sample performance:
Cross-validation
Regularization
Ensemble methods
We’ll return to IS/OOS evaluation in depth when we cover regression (Week 5).
Summary and Looking Ahead
Today’s Key Results
Part I: From Returns to Wealth
Log returns assumed normal \(\implies\) wealth is log-normal
Expected wealth includes a variance boost: \(\mathbb{E}[W_T] = W_0 e^{T\mu + T\sigma^2/2}\)
Mean \(>\) Median: most investors earn less than the expected value
Part II: Estimation Risk
We estimate \(\mu\) with error; this adds additional upward bias
Bias factor \(e^{T^2\sigma^2/2N}\) grows with horizon squared
Long-horizon wealth projections are doubly biased
Part III: The Normality Assumption Is Approximate
Returns have fat tails (excess kurtosis \(\approx 25\))
Extreme events happen far more often than normal predicts
Black Monday (1987): a 23-sigma event under normality
Part IV: Prediction Is Hard
Autocorrelations are tiny; most predictors fail out-of-sample
Overfitting is the enemy; out-of-sample testing is essential
What’s Next
Next week: Introduction to Machine Learning
What is ML? Traditional programming vs. learning from data
Types of learning: supervised, unsupervised, reinforcement
The ML formalism: models, loss functions, algorithms
Regression vs. classification
The rest of the course:
Clustering, regression, classification
Regularization and cross-validation
Ensemble methods, neural networks, text analysis
Today’s foundation carries through: We’re always estimating something from noisy data, always at risk of overfitting, always needing to check out-of-sample.